이 글은 관측(observability) 카테고리의 세 번째 글이자,
지표를 “보는 단계”에서 **“판단하는 단계”**로 끌어올리는 글이다.
p95는 언제 경고가 되고, p99는 언제 장애가 되는가
— 숫자에 의미를 부여하는 기준선 만들기
관측을 조금만 하다 보면
반드시 이 질문에 막힌다.
- “p95가 800ms면 괜찮은 건가요?”
- “p99가 튀는데, 이게 장애인가요?”
- “평균은 괜찮은데요?”
이 질문에 답하지 못하면
아무리 지표가 많아도
결정은 항상 늦어진다.
지표는 숫자가 아니라
‘행동 기준’이 될 때 의미가 있다.
1. 퍼센타일은 성능이 아니라 ‘사용자 분포’다
먼저 개념부터 정확히 고정하자.
p50 = 50th percentile = 50 퍼센타일
전체 데이터를 정렬했을 때,
하위 n% 지점에 해당하는 값
- p50 → 하위 50% 지점의 값. 즉, 중앙값(median). 절반의 사용자
- p95 → 느린 상위 5%
- p99 → 느린 상위 1%
즉,
p99는
“시스템의 평균 상태”가 아니라
“가장 불행한 사용자”를 본다.
그래서 퍼센타일은
성능 지표이면서 경험 지표다.
2. 평균이 항상 우리를 속이는 이유
이 상황을 떠올려보자.
- 요청 1000개
- 990개: 100ms
- 10개: 10초 <- 상위 1%는 서버 멈췄나? 를 경험
이때 평균은?
→ 약 200ms
그래프만 보면 이렇게 말한다.
“괜찮은데요?”
하지만 현실은 다르다.
10명은
이미 서비스를 망가진 것으로 느낀다.
그래서 평균은
운영 지표로 거의 쓸모가 없다.
퍼센타일은 성능 분석에서는 평균보다 훨씬 중요
3. p95가 먼저 흔들리는 이유
큐가 생기기 시작하면
지표는 항상 이 순서로 무너진다.
- 평균 → 거의 그대로
- p95 → 서서히 상승
- p99 → 급격히 상승
- 타임아웃 → 폭증
이건 우연이 아니다.
큐는
‘마지막에 들어온 요청’을
가장 오래 기다리게 한다.
그래서 p95 / p99는
큐의 조기 경보 장치다.

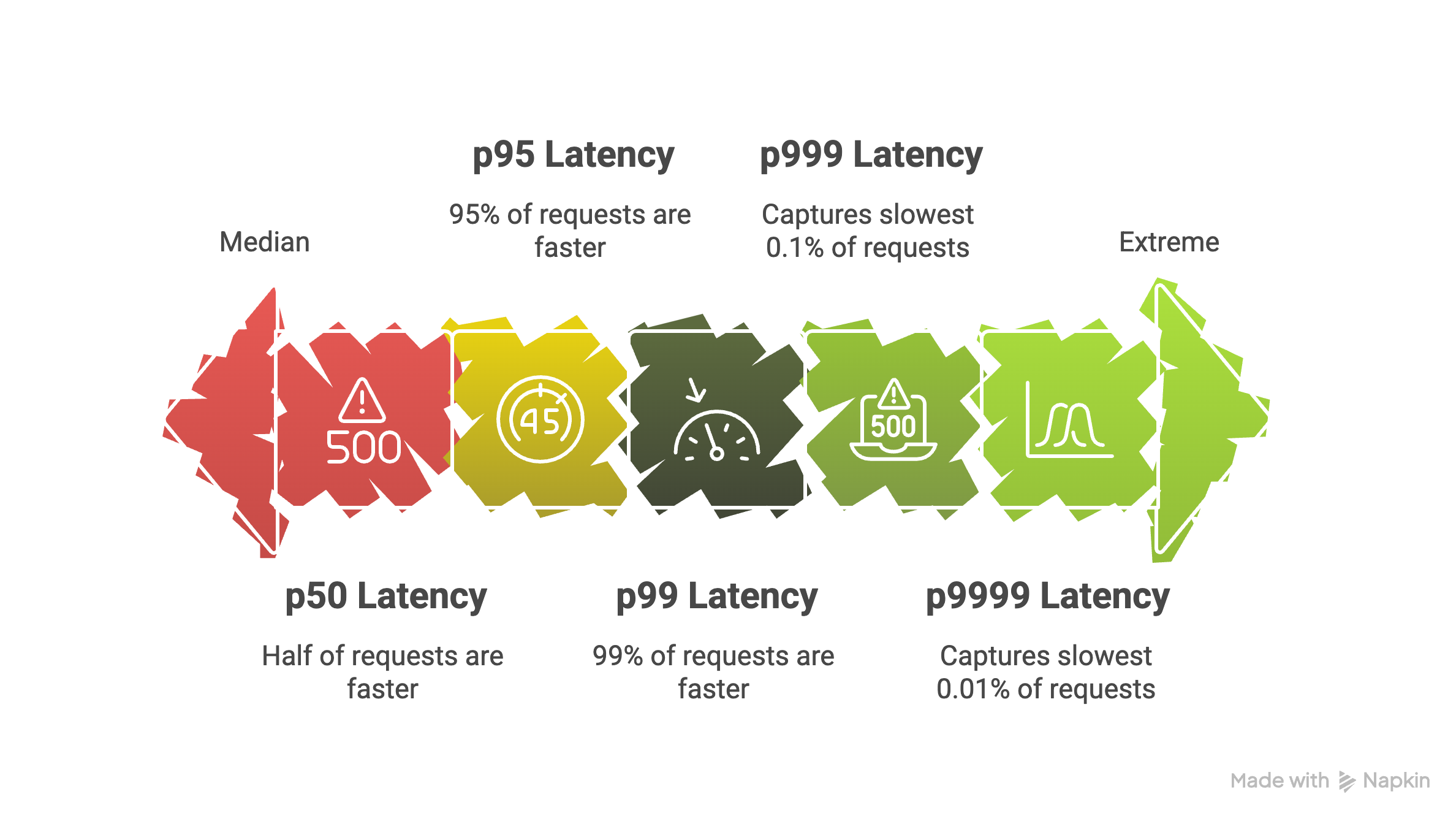
4. “그럼 p99만 보면 되나요?”
아니다.
이건 아주 흔한 실수다.
- p99만 보면 → 이미 늦다
- p50만 보면 → 아무것도 안 보인다
올바른 해석은 이거다.
p95는 구조의 신호고,
p99는 장애의 신호다.
5. 실무에서 써먹는 기준선 잡는 법
정답은 없다.
하지만 출발선은 있다.
이 질문부터 시작하자.
“이 요청은
몇 ms를 넘기면
사용자에게 ‘느리다’로 인식될까?”
그 답이 바로 p95 기준선이다.
예를 들면:
- 로그인 API
→ p95 = 300ms 초과 시 경고 - 조회 API
→ p95 = 500ms 초과 시 경고 - 배치성 API
→ p95 = 2s 초과 시 경고
6. p99는 언제 ‘장애’로 봐야 하나
p99는 이렇게 해석해야 한다.
p99가
평소보다 급격히 변했는가?
절대값보다 중요한 건 변화율이다.
- 평소 p99 = 600ms
- 갑자기 p99 = 2.5s
이건 명백한 신호다.
“큐가
빠르게 쌓이고 있다.”
7. Node.js와 Java에서 퍼센타일 해석 차이
Node.js
- p95/p99 상승 = 이벤트 루프 지연 가능성
- CPU는 낮을 수 있음
- 전체 요청이 같이 느려질 조짐
Java
- p95/p99 상승 = 스레드 대기 증가
- TPS는 유지될 수 있음
- 임계점 이후 급락 가능성
형태는 달라도
의미는 같다.
대기 시간이 늘고 있다.
8. 퍼센타일을 “알람”으로 쓰는 올바른 방법
이렇게 하면 실패한다.
- p99 > 1s → 장애
이렇게 해야 한다.
- p95 상승 추세 감지 → 경고
- p99 급등 → 즉시 대응
- 타임아웃 동반 → 장애 확정
퍼센타일은
단일 값이 아니라
흐름으로 본다.
9. 퍼센타일이 말해주는 진짜 질문
지표가 던지는 질문은 이거다.
“누가,
언제부터,
얼마나 기다리고 있는가?”
이 질문에 답할 수 있으면
관측은 이미 성공이다.
10. 한 문장으로 이 글을 닫자
p95는
시스템이 흔들리기 시작했다는 신호이고,
p99는
이미 사용자 경험이 무너졌다는 증거다.
다음 글 예고
이제 남은 마지막 질문은 이것이다.
“그럼
이 신호를 보고
어디부터 손대야 하는가?”
다음 글에서는
관측을 행동으로 바꾸는 순서를 다룬다.
느림을 봤을 때
절대 하지 말아야 할 것들,
가장 먼저 해야 할 것들
— 성능 장애 대응의 우선순위
이제 관측은
결정의 도구가 된다.
'system_fundamentals > observability' 카테고리의 다른 글
| 관측이란 무엇을 보는 기술이 아니라 언제 행동할지를 정하는 기술 (0) | 2026.01.05 |
|---|---|
| 장애는 언제나 미리 신호를 보낸다 (0) | 2026.01.05 |
| 느림을 봤을 때 절대 하지 말아야 할 것들, 가장 먼저 해야 할 것들 (0) | 2026.01.05 |
| 큐와 대기는 어떤 지표로 드러나는가 (0) | 2026.01.05 |
| 우리는 무엇을, 어디서, 어떻게 봐야 하는가 (0) | 2026.01.05 |




댓글